I'm from Pakistan and currently working as a Graduate Fellow at Visual Computing Lab which is a part of the prestigious ISTI-CNR research institute located in Pisa, Italy. I am also pursuing my PhD studies at University of Pisa. My research focuses on user-assisted 3D reconstruction and in this context, I am working on the improvements in MoReLab.
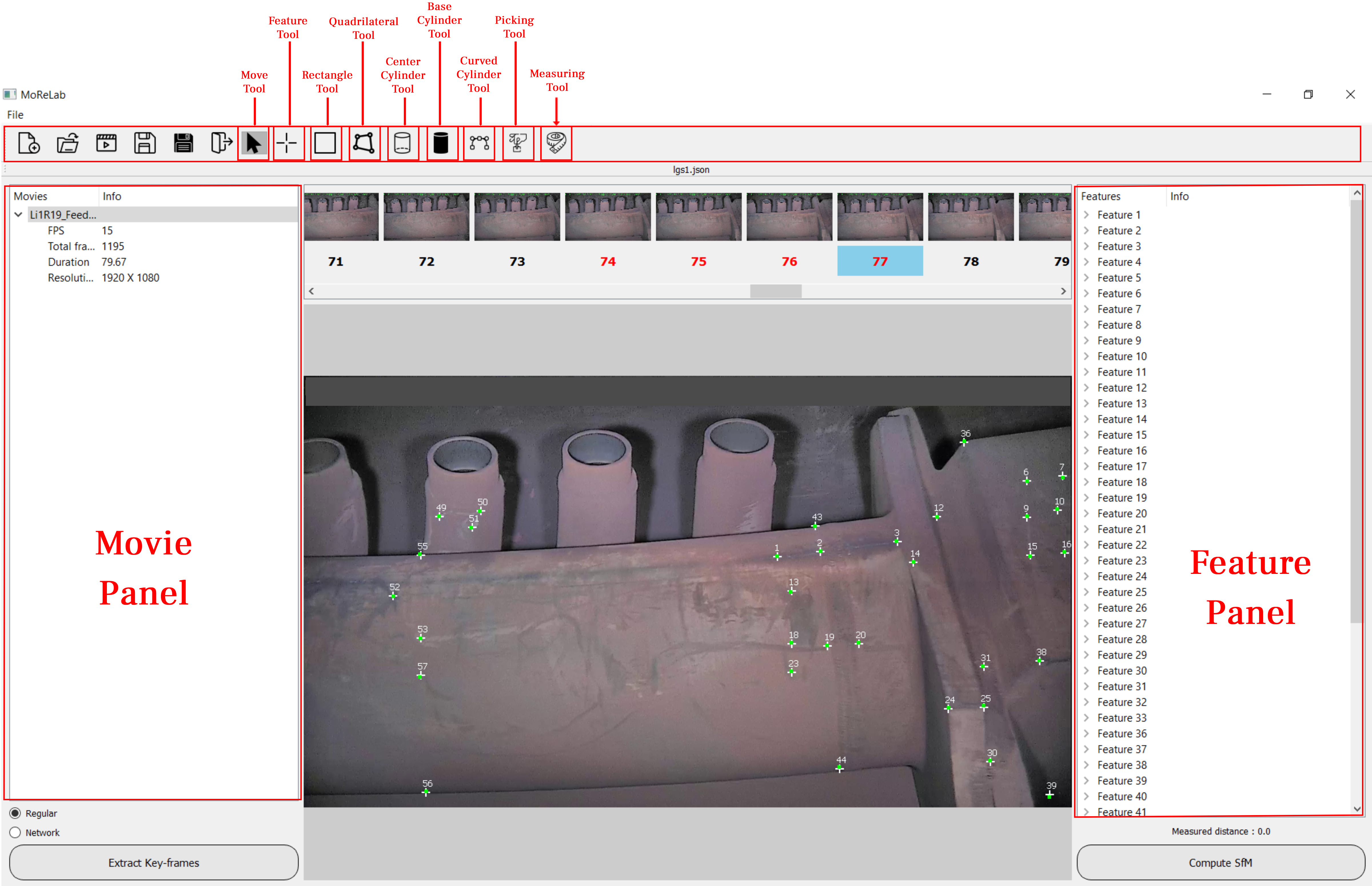
I was recruited for ESR07 position in EVOCATION ITN. I Developed a PyQt based graphical user interface called MoReLab to perform user-assisted 3D reconstruction. MoReLab allows the user to add features manually instead of automatic feature detection and matching. Bundle adjustment computes a sparse 3D point cloud for manually added feature correspondences. After this, the user can use several primitive shape tools e.g., quadrilateral, cylinder, tube etc. to model different objects and export 3D mesh. MoReLab also allows the user to measure distance between any 3D points..
I worked as a Teaching Assistant for the course of Sensors, Perception and Actuation with instructor Ilya Afanasyev. My responsibility was to mark all homeworks, quizzes and exams according to instructor's guidelines.
ROS for beginners: Basics, Motion and OpenCV [certificate].
ROS for Beginners II: Localization, Navigation and SLAM [certificate].
MoReLab: A software for user-assisted 3D reconstruction [pdf] [code]
We present MoReLab, a tool for user-assisted 3D reconstruction. This reconstruction requires an understanding of the shapes of the desired objects. Our experiments demonstrate that existing Structure from Motion (SfM) software packages fail to estimate accurate 3D models in low-quality videos due to several issues such as low resolution, featureless surfaces, low lighting, etc. In such scenarios, which are common for industrial utility companies, user assistance becomes necessary to create reliable 3D models. In our system, the user first needs to add features and correspondences manually on multiple video frames. Then, classic camera calibration and bundle adjustment are applied. At this point, MoReLab provides several primitive shape tools such as rectangles, cylinders, curved cylinders, etc., to model different parts of the scene and export 3D meshes. These shapes are essential for modeling industrial equipment whose videos are typically captured by utility companies with old video cameras (low resolution, compression artifacts, etc.) and in disadvantageous lighting conditions (low lighting, torchlight attached to the video camera, etc.). We evaluate our tool on real industrial case scenarios and compare it against existing approaches. Visual comparisons and quantitative results show that MoReLab achieves superior results with regard to other user-interactive 3D modeling tools.
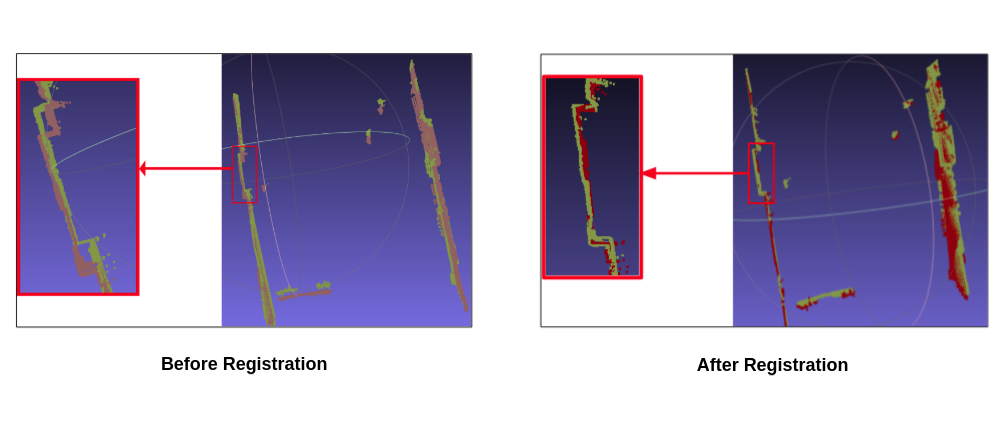
Evaluating deep learning methods for low resolution point cloud registration in outdoor scenarios [pdf]
Point cloud registration is a fundamental task in 3D reconstruction and environment perception. We explore the performance of modern Deep Learning-based registration techniques, in particular Deep Global Registration (DGR) and Learning Multi-view Registration (LMVR), on an outdoor real world data consisting of thousands of range maps of a building acquired by a Velodyne LIDAR mounted on a drone. We used these pairwise registration methods in a sequential pipeline to obtain an initial rough registration. The output of this pipeline can be further globally refined. This simple registration pipeline allow us to assess if these modern methods are able to deal with this low quality data. Our experiments demonstrated that, despite some design choices adopted to take into account the peculiarities of the data, more work is required to improve the results of the registration.
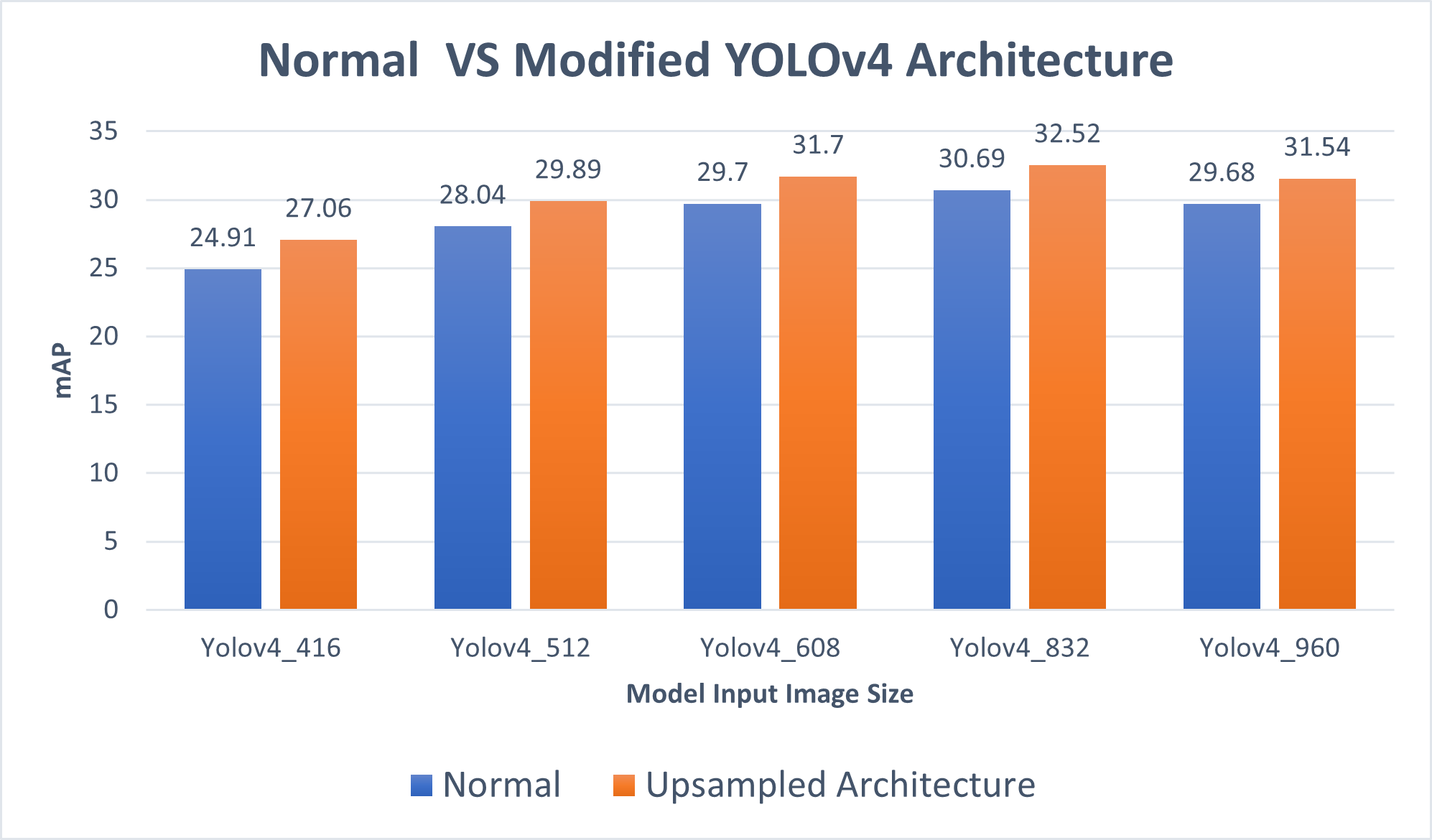
Improved Yolov4 for aerial object detection [pdf] [code]
Drones equipped with cameras are being used for surveillance purposes. These surveillance systems need vision-based object detection of ground objects which look very small because of the altitude of drones. We propose an improved YOLOv4 model targeted for vision-based small object detection. We investigated the performance of state of the art YOLOv4 object detector on the VisDrone dataset. We enhanced the features of small objects by connecting Upsampling layers and concatenating the upsampled features with the original features to obtain more refined and grained features for small objects. Experiments showed that the modified YOLOv4 achieved 2 percent better mAP results as compared to the original YOLOv4 at different image resolutions on the VisDrone dataset while running at the same speed as the original YOLOv4.
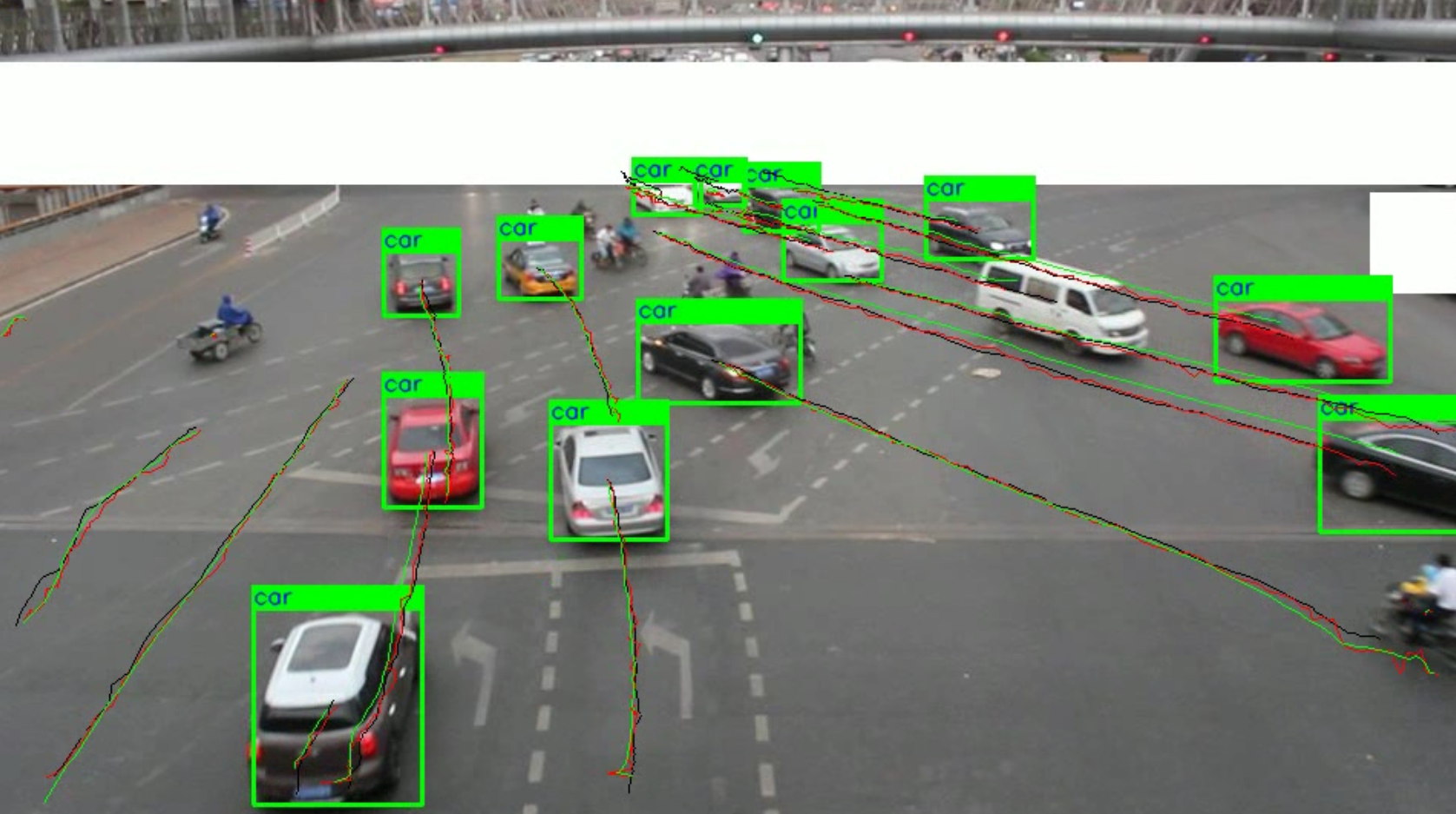
Deep learning based trajectory estimation of vehicles in crowded and crossroad scenarios [pdf] [code][video]
[talk]
The rapid developments in the field of Artificial Intelligence are bringing enhancements in the area of intelligent transport systems by overcoming the challenges of safety concerns. Traffic surveillance systems based on CCTV cameras can help us to achieve safe and sustainable transport systems. Trajectory estimation of vehicles is an important part of traffic surveillance systems and self-driving cars. The task is challenging due to the variations in illumination intensities, object sizes and real-time detection. We propose tracking by detection based trajectory estimation pipeline which consists of two stages: The first stage is the detection and localization of vehicles and the second stage is building associations in bounding boxes and track the associated bounding boxes. We analyze the performance of the Mask RCNN benchmark and YOLOv3 on the UA-DETRAC dataset and evaluate certain metrics like Intersection over Union, Precision-Recall curve, and Mean Average Precision. Experiments show that Mask RCNN Benchmark outperforms YOLOv3 in terms of accuracy. SORT tracker is applied on detected bounding boxes to estimate trajectories. The tracker is evaluated using mean absolute error. We demonstrate that the developed technique works successfully in crowded and crossroad scenarios.
ROS-based integration of smart space and mobile robot as internet of robotic things [pdf] [code]
The Internet of Robotic Things is a concept that is rapidly gaining traction in the robotics industry. As the field of robotics advances, one of the obstacles to its widespread adoption remains the high cost of purchasing and maintaining robot. Although the gap is continuously closing, robots these days cannot make decisions with the efficiency that humans can. People are spatially aware, and we can perceive and understand changes in the environment that robots are not capable of. This paper attempts to propose how a smart space can be implemented to increase the spatial awareness of a robot by providing more data to make better informed decisions. We focus on using the Robot Operating System (ROS) as a framework to integrate Smart Space and a mobile robot to expand the robots sensory information and make collision avoidance decisions.
Moving vehicle detection in wide area motion imagery (WAMI) [code]
This project aims to detect and track very small moving vehicles in high altitude wide area motion images. CenterTrack algorithm was trained on moving vehicles in WPAFB 2009 dataset and results were compared with state of the art. The trained algorithm was found 8 times faster than the existing algorithms while achieving similar accuracy.